Auf meinem HC4 NAS soll Calibre die Bibliotheksverwaltung meiner eBooks übernehmen. Hier wird die Installation beschrieben.
Seit Mitte 2022 ist die Version 6.0 von Calibre verfügbar, welche die ARM CPU Architektur unter Linux unterstützt. Es waren bisher zwar auch Debian-Pakete für Calibre verfügbar, diese waren aber meist veraltet. Calibre empfielt explizit, keine Distro-Pakete einzusetzen und statdessen ihren Installer zu verwenden.
Installation
Notwendige Pakages installieren
- python ≥ 3.3 => armbian liefert bereits 3.10 mit.
- xdg-utils
- wget => wget bereits auf armbian installiert.
- xz-utils
- libegl1
- libopengl0
sudo apt-get install xdg-utils
sudo apt-get install xz-utils
sudo apt-get install libegl1
sudo apt-get install libopengl0
Nun kann Calibre über das installer-Skript installiert werden. Ich führe eine isolierte Installation durch und installiere Calibre auf einem eigens dafür eingerichteten Platz auf der HDD:
wget -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sh /dev/stdin install_dir=/mnt/program_data/calibre-bin isolated=y
Damit ist Calibre unter /mnt/program_data/calibre-bin installiert. Calibre ist eine Desktop Anwendung, welche über eine Server-Komponente verfügt. Logischerweise kann Calibre selber nicht gestartet werden, da wir ja einen headless Server einsetzen. Folgender Aufruf führt entsprechend zu einem Fehler:
/mnt/program_data/calibre-bin/calibre/calibre
Um die Server-Komponente starten zu können, müssen noch einige Schritte getan werden:
cd /mnt/program_data/calibre-bin
mkdir mkdir calibre-library
cd calibre-library
irgend ein eBook herunterladen
wget http://www.gutenberg.org/ebooks/46.kindle.noimages -O christmascarol.mobi
Das Buch der Calibre-db hinzufügen:
cd /mnt/program_data/calibre-bin/calibre
./calibredb add /mnt/program_data/calibre-bin/calibre-library/*.mobi --with-library /mnt/program_data/calibre-bin/calibre-library/Calibre
Damit wurde eine Calibre Library unter /mnt/program_data/calibre-bin/calibre-library/Calibre erstellt und gleichzeitig das Buch hinzugefügt.
Nun kann der Calibre-Server gestartet werden. Da ich den Standart-Port 8080 breits verwende, weise ich über den Parameter –port den Port 8081 zu:
cd /mnt/program_data/calibre-bin/calibre
./calibre-server --port 8081 /mnt/program_data/calibre-bin/calibre-library/Calibre
Nun, da der Server läuft, kann man das Web-Interface aufrufen:
http://192.168.x.xxx:8081
Service erstellen
Achtung: Dieser Service soll nach dem mounten der btrfs Shares durchgeführt werden. Es ist daher nötig, die Reihenfolge der Services zu beeinflussen. Hier habe ich beschrieben wie ich das konkret umgesetzt habe.
sudo vi /etc/systemd/system/calibre-server.service
## startup service
[Unit]
Description=calibre content server
After=runlevel4.target => eigenes Target siehe https://www.dev-metal.ch/?p=1913
[Service]
Type=simple
User=xxx
Group=<Gruppe, welche Schreibzugriff auf /mnt/multimedia/books hat>
ExecStart=/mnt/program_data/calibre-bin/calibre/calibre-server --port 8081 /mnt/program_data/calibre-bin/calibre-library/Calibre --enable-local-write
[Install]
WantedBy=multi-user.target => eigenes Target siehe https://www.dev-metal.ch/?p=1913
sudo systemctl enable calibre-server
sudo service calibre-server start
Ab sofort wird Calibre-Server als Service beim System-Boot mit gestartet.
Die Bücherbilbiothek Calibre hinzufügen
Ich verfüge bereits über sehr viele eBooks, welches sich unter /mnt/multimeda/books befinden. Dies können nun der Calibre-DB hinzugefügt werden:
./calibredb add /mnt/multimedia/books/ -r --with-library http://localhost:8081#Calibre
Zu beachten ist hier, dass für den library-pfad die lokale http URL verwendet wird. Dies ist nötig, weil calibredb ansonsten den Aufruf bei laufendem Server nicht erlaubt. Da wir den Service mit –enable-local-write gestartet haben, kann calibredb über die lokale URL (localhost) dennoch direkte Bücher hinzufügen.
Im weiteren werden hier die Bücher von /mnt/multimedia/books nach Calibre kopiert.
Automatisch Bücher der Bibliothek hinzufügen
Es gäbe die Möglichkeit einen „Listener-Ordner“ zu definieren, über welchem calibredb dann jeweils Bücher direkt importiert. Dann müssten die bücher nur in diesen Ordner kopiert werden und diese würden dann automatisch nach Calibre eingelesen: https://www.digitalocean.com/community/tutorials/how-to-create-a-calibre-ebook-server-on-ubuntu-20-04#step-6-mdash-optional-automatically-adding-books-to-your-calibre-library
Dies verwende ich aber (mal bis auf weiteres) nicht, da Bücher auch elegant über die Weboberfläche von Calibre oder Calibre-Web hochgeladen werden können.
Calibre-web
Das Standard- Web-Interface von Calibre ist zwar zu gebrauchen, aber sicher nicht „state of the art“. Es gibt ein Projekt „Calibre-Web„, welches ein schöneres Interface für die Verwaltung einer Calibre Datenbank bietet (https://github.com/janeczku/calibre-web/wiki/Manual-installation):
sudo apt install python3-pip python3-venv python3-dev
Installations-Verzeichnis erstellen:
mkdir /mnt/program_data/calibre-bin/calibre-web
cd /mnt/program_data/calibre-bin/calibre-web
Virtuelle Umgebung für calibre-web in ordner venv erstellen
python3 -m venv venv
Calibreweb in virutelle Umgebung installieren:
cd /mnt/program_data/calibre-bin/calibre-web
./venv/bin/python3 -m pip install calibreweb
Calibre-Web starten
./venv/bin/python3 -m calibreweb
URL öffnen
http://192.168.x.x:8083
Login
Default admin login:
Username: admin
Password: admin123
Calibre Datenbank konfigurieren
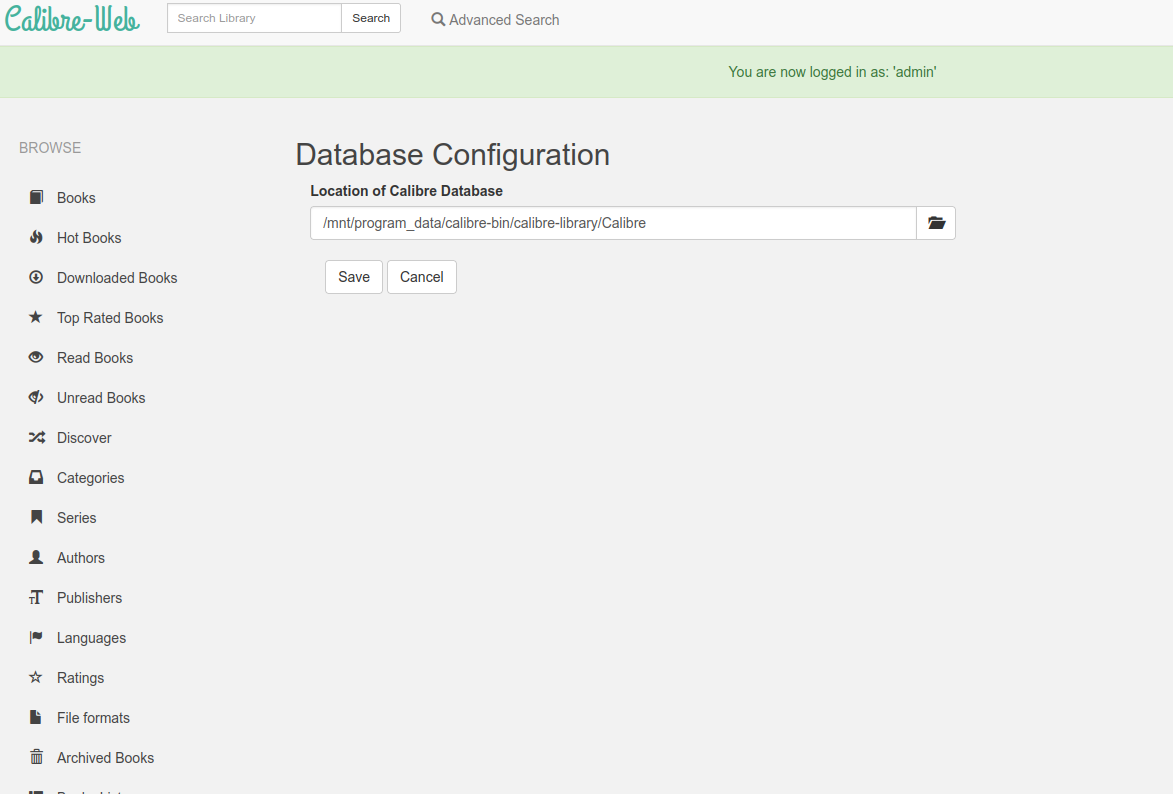
Calibre-Web Konfig Files
Alle Konfig-Files (settings database, logfiles) befinden sich unter
cd /homes/[username]/.calibre-web
zusätzlichen Konfig-Files (für gdrive, gmail, etc.) sind dort zu konfigurieren.
Calibre-Web als Service installieren
Siehe https://github.com/janeczku/calibre-web/wiki/Setup-Service-on-Linux#start-calibre-web-as-service-under-linux-with-systemd
Achtung: Dieser Service soll nach dem mounten der btrfs Shares durchgeführt werden. Es ist daher nötig, die Reihenfolge der Services zu beeinflussen. Hier habe ich beschrieben wie ich das konkret umgesetzt habe.
Service File erstellen
sudo vi /etc/systemd/system/cps.service
[Unit]
Description=Calibre-Web
After=runlevel4.target => eigenes Target. Siehe https://www.dev-metal.ch/?p=1913
[Service]
Type=simple
User=ralwet
ExecStart=/mnt/program_data/calibre-bin/calibre-web/venv/bin/python3 -m calibreweb
[Install]
WantedBy=multi-user.target => eigenes Target. Siehe https://www.dev-metal.ch/?p=1913
Service aktivieren
sudo systemctl enable cps.service
Service starten
sudo service cps status
Gut zu wissen:
Installations-Pfad
Hier wird die Installation über den pip paket-manager durchgeführt. Wenn man wissen will, wo calibre-web effektiv installiert ist:
/mnt/program_data/calibre-bin/calibre-web/venv/bin/pip show calibreweb
Name: calibreweb
Version: 0.6.19
Summary: Web app for browsing, reading and downloading eBooks stored in a Calibre database.
Home-page: https://github.com/janeczku/calibre-web
Author: @OzzieIsaacs
Author-email: Ozzie.Fernandez.Isaacs@googlemail.com
License: GPLv3+
Location: /mnt/program_data/calibre-bin/calibre-web/venv/lib/python3.10/site-packages
Requires: advocate, APScheduler, Babel, backports-abc, chardet, Flask, Flask-Babel, Flask-Login, Flask-Principal, flask-wtf, iso-639, lxml, PyPDF3, pytz, requests, SQLAlchemy, tornado, unidecode, Wand, werkzeug
Required-by:
Security-Header
Der Security-Header kann hier angepasst werden. => Man muss aber wissen was man tut… 😉
vi /mnt/program_data/calibre-bin/calibre-web/venv/lib/python3.10/site-packages/calibreweb/cps/web.py
@app.after_request
def add_security_headers(resp):
# csp = "default-src 'self'"
# csp += ''.join([' ' + host for host in config.config_trustedhosts.strip().split(',')])
# csp += " 'unsafe-inline' 'unsafe-eval'; font-src 'self' data:; img-src 'self' "
# if request.path.startswith("/author/") and config.config_use_goodreads:
# csp += "images.gr-assets.com i.gr-assets.com s.gr-assets.com"
# csp += " data:"
# resp.headers['Content-Security-Policy'] = csp
# if request.endpoint == "edit-book.show_edit_book" or config.config_use_google_drive:
# resp.headers['Content-Security-Policy'] += " *"
# elif request.endpoint == "web.read_book":
# resp.headers['Content-Security-Policy'] += " blob:;style-src-elem 'self' blob: 'unsafe-inline';"
# resp.headers['X-Content-Type-Options'] = 'nosniff'
# resp.headers['X-Frame-Options'] = 'SAMEORIGIN'
# resp.headers['X-XSS-Protection'] = '1; mode=block'
# resp.headers['Strict-Transport-Security'] = 'max-age=31536000;'
return resp
Links




{kind=link}